# Tailpipe's next evolution: Building on DuckLake
> Tailpipe adopts DuckLake, DuckDB's new lakehouse format, delivering better query performance and setting the foundation for cloud-scale log analysis.
By Turbot Team
Published: 2025-09-22
Tailpipe is evolving. We're migrating from raw Parquet files to [DuckLake](https://duckdb.org/2025/05/27/ducklake.html), DuckDB's cutting-edge lakehouse format. This architectural shift delivers immediate performance improvements while laying the groundwork for Tailpipe's expansion into [Turbot Pipes](https://turbot.com/pipes).
DuckLake represents a fundamental advancement in how we store and query your security logs. By combining the efficiency of Parquet files with intelligent metadata management, we're ready to handle log analysis at any scale; from gigabytes on your laptop to petabytes in the cloud.
## What is DuckLake?
DuckLake is DuckDB's new lakehouse format that bridges the gap between data lakes and data warehouses. It provides the best of both worlds: the open, scalable storage of a data lake with the structured, query-optimized capabilities of a data warehouse.
At its core, DuckLake consists of:
- **Data layer**: Parquet files providing efficient columnar storage
- **Metadata layer**: SQL database tracking schemas, partitions, statistics, and transactions
- **Query engine**: DuckDB's powerful analytics engine optimized for the format
This combination creates a structured, query-friendly layer on top of plain Parquet files, delivering the performance and features needed for modern log analysis.
## The technical transformation
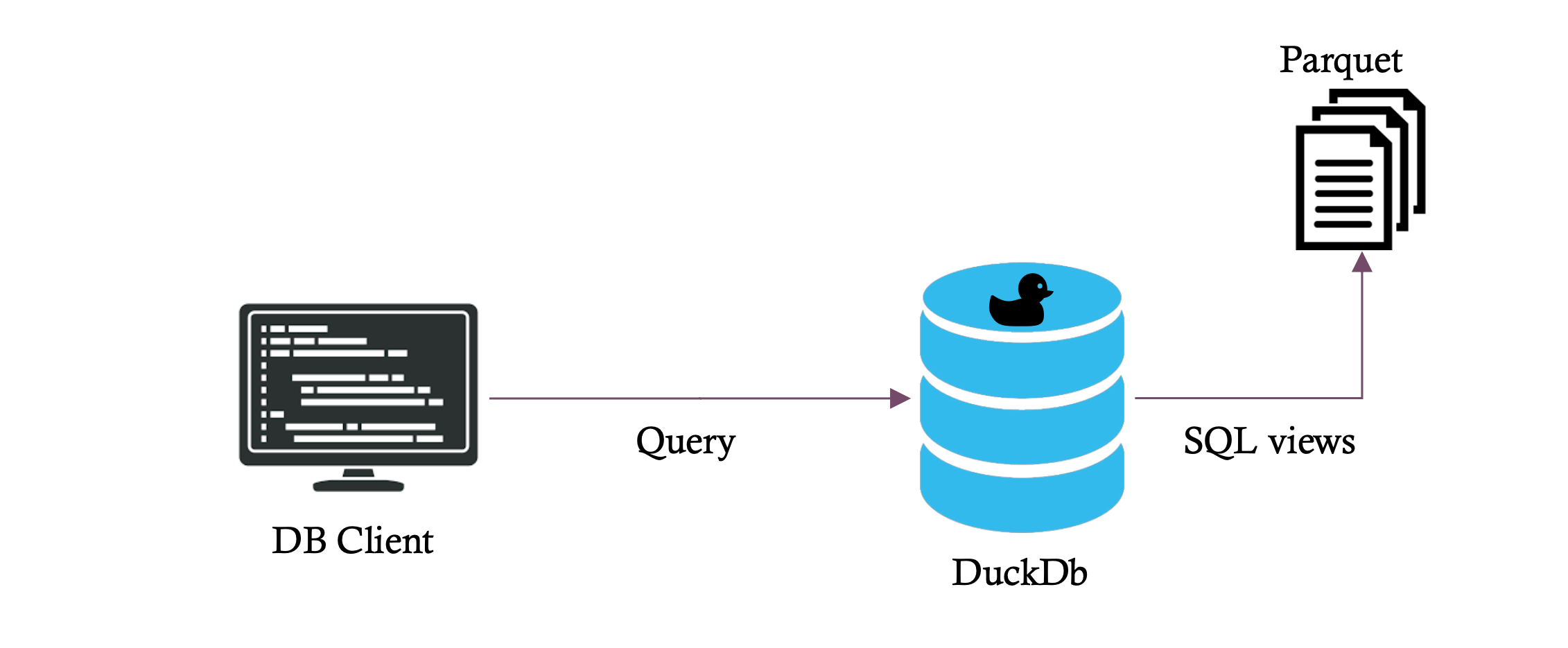
### Current architecture
Today, Tailpipe stores your logs as raw Parquet files with DuckDB views providing the query interface. When you query `aws_cloudtrail`, DuckDB reads through potentially thousands of files to find your data. While this works well for local queries, it becomes challenging at scale.
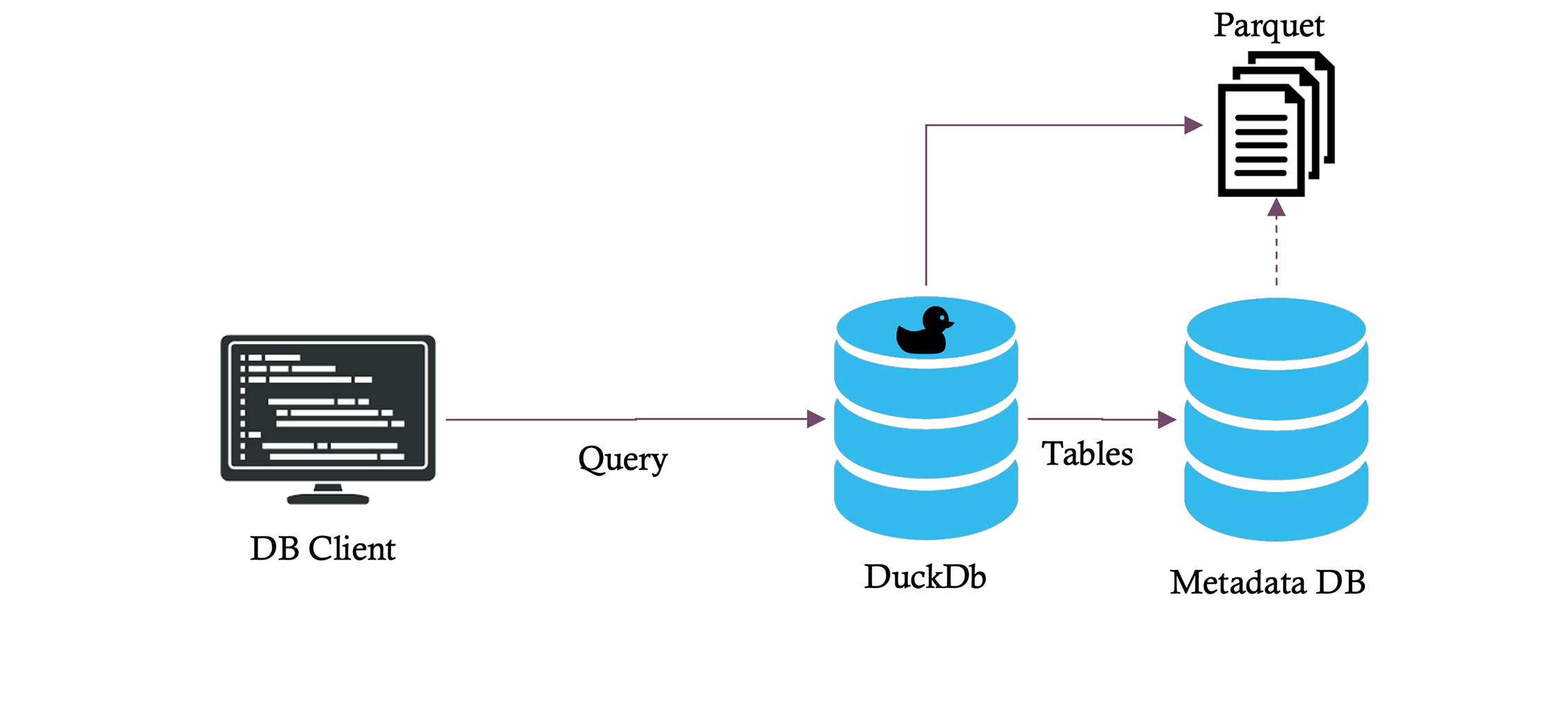
### New architecture with DuckLake
With DuckLake, we maintain the same Parquet files but add a metadata database that tracks everything about your data. DuckDB now queries proper tables backed by intelligent metadata, dramatically reducing the number of files it needs to read.
In our testing with 20 million CloudTrail log entries, a time-range query that previously read 1,463 files now reads just 2 files: a 700x reduction in file operations.
## Immediate benefits
While the migration is largely transparent to users, you'll notice several improvements:
### Smarter partitioning
DuckLake enables function-based partitioning, eliminating the need for separate date columns. You can now filter directly on `timestamp` fields, and DuckLake automatically determines the minimal set of files to read.
```sql
-- Before: Required filtering on both tp_date and timestamp
select * from aws_cloudtrail
where tp_date = '2025-09-10'
and timestamp between '2025-09-10 08:00:00' and '2025-09-10 09:00:00'
-- After: Just filter on timestamp
select * from aws_cloudtrail
where timestamp between '2025-09-10 08:00:00' and '2025-09-10 09:00:00'
```
### Performance improvements
Query performance improves across the board, especially for time-range queries(the most common pattern in security log analysis). Collection times also show modest improvements as DuckLake optimizes write operations.
### Future-proof architecture
DuckLake provides critical capabilities for Tailpipe's future:
- **Schema evolution**: Graceful handling of log format changes over time
- **Transaction support**: ACID guarantees for reliable data operations
- **Concurrent access**: Multiple writers with proper database backends
- **Rich metadata**: Statistics and optimization hints for better query planning
## Setting the stage for Pipes
This migration is a critical step toward bringing Tailpipe to Turbot Pipes. Cloud deployments require different architectural patterns than local CLI tools—patterns that DuckLake handles natively.
With DuckLake's object storage support, we can efficiently query logs without maintaining massive local caches. Its metadata layer enables intelligent caching strategies, keeping frequently accessed data fast while seamlessly retrieving historical data from object storage.
The concurrent write capabilities mean multiple collection sources can feed into the same Tailpipe instance, essential for centralized log analysis in Pipes. Schema evolution ensures your queries keep working even as cloud providers update their log formats.
## Seamless migration
When you upgrade to the new Tailpipe version, we'll automatically detect and migrate your existing data to DuckLake format. The migration:
- Preserves all your existing log data
- Creates a backup of the original files
- Maintains backward compatibility for queries
- Requires no manual intervention
Simply run any Tailpipe command after upgrading, and we'll handle the rest.
## Partnering with innovation
By adopting DuckLake early, we're aligning with DuckDB's vision for the future of analytical data management. The DuckDB team is actively developing the platform—when we reported an issue during development, we received a solution within four minutes.
This partnership ensures Tailpipe benefits from ongoing improvements in query optimization, caching strategies, and cloud integration. As DuckLake evolves, so does Tailpipe's capability to handle your growing log analysis needs.
## Looking ahead
DuckLake positions Tailpipe for ambitious future capabilities:
- **Federated queries** across multiple log sources
- **Incremental materialization** for real-time dashboards
- **Advanced caching** for hybrid cloud/local deployments
- **Multi-tenant isolation** for shared Pipes environments
We're building on a foundation designed for the scale and complexity of modern cloud infrastructure.
## See it in action
## Ready for what's next
The DuckLake capabilities are available today. Your existing workflows continue unchanged: same queries, same commands, better performance.
The DuckLake migration is now available in the [latest Tailpipe CLI release](https://tailpipe.io/downloads). Your existing workflows continue unchanged: same queries, same commands, better performance. And [let us know](https://turbot.com/community/join) how DuckLake improves your security investigations and compliance reporting!